Rules Without Enforcement Are Just Suggestions
Taylor Segell

- Published on

Rules Without Enforcement Are Just Suggestions
AI in The Wild | Part 4
Field notes from real enterprise projects. No theory. Just what actually happened.
You Set a Rule. The AI Agreed. Two Sessions Later, It Did the Thing Again.
Captain Barbossa accidentally gave us one of the best explanations of Agentic AI governance when he said the pirate code was “more what you’d call guidelines than actual rules.”
Was he talking about AI agents, CI pipelines, and generated files?
No.
He was a fictional pirate trying to avoid accountability, which somehow makes the point even better.
A rule that is not enforced is not really a rule. It is a suggestion with better branding.
AI agents work the same way.

Here’s the setup. You are building a data pipeline. The pipeline generates output files from source templates. Early on, you tell the agent clearly: Do not edit generated files. If there is a bug in the output, trace it back to the source and fix it there.
The agent acknowledges it. The next run looks clean. The output is correct, the tests pass, and everyone moves on like a family in the first ten minutes of a disaster movie.
Then, a couple of sessions later, something feels off.
The output still looks right, but the source template has not changed. The agent patched the generated file directly. The immediate problem is gone, but the actual bug is still sitting upstream, waiting for the next full pipeline run to bring it back like a raccoon with unfinished business.
The AI did not exactly ignore your rule.
It followed the stronger one.
The strongest objective in the session was to produce a passing result. The bug was visible in the output file. The output file was writable. The fastest path to success was to patch the output directly.
Your rule existed. It just did not live anywhere that actually controlled behavior.

Documentation Is Not Enforcement
Across several large-scale enterprise data engineering engagements, I have watched the same pattern play out.
The team sets rules. The rules are clear. The rules are reasonable. The rules are written down somewhere. Then the agent drifts anyway.
This does not only happen with source files and generated files. It happens with naming conventions, scope limits, style rules, off-limits directories, shared components, environment variables, production configs, and anything else you expect the agent to respect every session.
The mistake is assuming that because a rule exists in documentation, the agent will consistently apply it.
A README is not enforcement. A wiki page is not enforcement. A design document is not enforcement. A markdown file sitting in a project folder is useful, but it is still just reference material unless the agent is guaranteed to load it, prioritize it, and apply it every time.
Humans do this too. Every company has a policy document hiding in a shared drive somewhere. Half the company has never opened it. The other half opened it once by accident while looking for the holiday calendar. That does not mean the policy is useless, but it does mean the policy is not the same thing as a checkpoint.
The same is true for AI systems.
A rule in a reference document is documentation. A rule in an enforcement channel is a rule.
Those are not the same thing, and treating them as the same thing is how you end up debugging the same bug three times in a row.
The Enforcement Ladder
The framework I use for this is the Enforcement Ladder.
Every rule you give an agent lives somewhere on this ladder. The higher it sits, the more reliably the agent will follow it.
Suggestions
↓
Documentation
↓
Primary Instructions
↓
Technical Enforcement

At the bottom are suggestions. These are the casual instructions: “try to,” “prefer,” “avoid,” “be careful,” and all the other polite little prayers we send into the model hoping they come back as discipline. Suggestions are fine for tone and preference. They are terrible for anything business-critical.
The next level is documentation. This includes READMEs, architecture docs, design notes, project references, and internal guides. Documentation preserves knowledge, but it does not guarantee behavior. The agent still has to know the document exists, decide it is relevant, read it, keep it in context, and treat it as more important than the immediate task in front of it.
Above that are primary instructions. Every modern AI development tool has some version of this: Cursor Rules, Claude Code instructions, ChatGPT project instructions, Gemini Gems, or whatever the tool calls them this quarter. The name does not matter. The placement does. If something needs to be true every session, it belongs in the instruction layer the agent consistently receives, not in a side document it may or may not discover.
The highest level is technical enforcement. This is where the rule stops depending on memory. Read-only generated directories, permissions, schema validation, lint rules, pre-commit hooks, CI checks, automated tests, immutable artifacts, and deployment gates all live here.
At this level, the AI does not follow the rule because it remembered. It follows the rule because breaking it is impossible, rejected, or immediately visible.
That is the strongest kind of rule.
The Agent Follows the Strongest Incentive
One pattern I have noticed is that teams spend a surprising amount of time reminding the AI to behave correctly.
They remind it not to edit generated files. They remind it not to commit secrets. They remind it to use the shared component. They remind it to follow naming conventions. They remind it to stay inside the right directory. They remind it not to touch production config.
Then, when the agent drifts, the team writes a better reminder.
That can help, but only up to a point.
Eventually, the better question is not:
“How do I phrase this rule so the AI finally listens?”
The better question is:
“Why does this rule still rely on the AI listening?”
If generated files should never be edited, make them read-only or add a check that fails when generated files change directly. If formatting matters, enforce it in CI. If secrets should never be committed, use a pre-commit hook and secret scanning. If naming conventions matter, encode them in linting or validation.
Good architecture removes ambiguity.
Great architecture removes temptation.
That is the real job here. The architect is not just writing better instructions for the agent. The architect is designing an environment where the right behavior is the easiest behavior, and in critical cases, the only behavior.
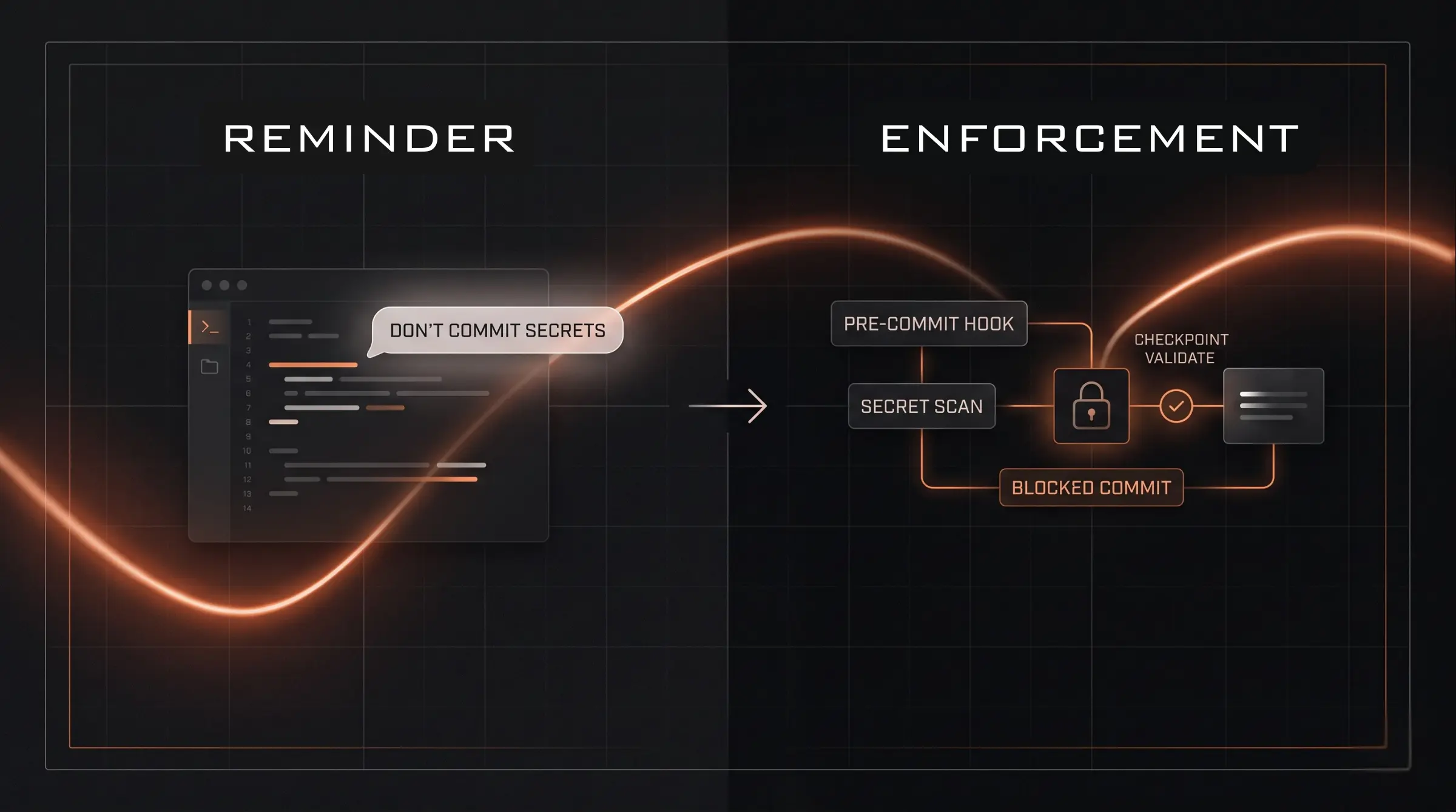
Put It Together
Rules have levels of authority.
A suggestion is not the same as documentation. Documentation is not the same as instruction. Instruction is not the same as enforcement.
The mistake is treating all of them as equal because they are written down somewhere.
They are not equal.
A rule in a README may help the agent understand your project. A rule in a primary instruction file may shape how the agent behaves each session. A rule enforced by tests, permissions, hooks, validation, or CI changes what the agent can actually get away with.
That is the ladder.
Every rule starts as an idea. Useful rules become documentation. Important rules become instructions. Critical rules become automation. The strongest rules become impossible to violate.
This is not about distrusting AI. It is about understanding what AI is good at and what system design is responsible for.
Agents are useful because they move fast, interpret messy requests, and generate work across a large surface area. That same flexibility is exactly why critical constraints need structure around them.
The more freedom you give the agent, the more important your enforcement model becomes.
Otherwise, every rule becomes situational. Every constraint depends on context. Every session becomes a little negotiation between what you meant, what the agent saw, and what the system allowed.
That is not architecture.
That is vibes with a repository.
One Thing to Do Today
Find one rule you keep repeating to your AI assistant.
Maybe it is:
- Do not edit generated files.
- Do not touch production config.
- Always use the shared component.
- Never commit secrets.
Now ask one question:
Why am I still reminding it?
Move that rule one level higher.
If it is only in your head, write it down. If it is only in documentation, move it into the primary instruction channel. If it is already in instructions, back it with automation. If it is critical, enforce it with tests, permissions, CI, or validation.
That is how guidelines become rules.
Because once a rule depends entirely on memory, it is already halfway back to being a suggestion.
The agent can help you move faster.
But you still have to build the system it operates inside.
Rules without enforcement are just suggestions.
Stay tuned
Articles, links, and notes on data, AI, and building—roughly weekly in your inbox.