The Agent is NOT The Architect
Taylor Segell

- Published on

The Agent Is Not the Architect
AI in The Wild | Part I
Field notes from real enterprise projects. No theory. Just what actually happened.
You’re three weeks into an AI-assisted build, and everything looks great.
You’ve been working with an AI coding assistant on a new data pipeline. The output is clean. The logic looks right. Your stakeholders are nodding along. You are starting to think, dangerously, that maybe this whole thing is actually going to work.
Then you run the exact same input twice and get two different answers.
Nobody changed anything. Same input. Same environment. Same code. Different output.
You spend an hour reviewing the logic, checking the data, checking the environment, and slowly wondering if you have somehow broken determinism as a concept.
You didn’t.
The pipeline was working exactly as designed. The problem is that “exactly as designed” included an AI making a routing decision that should have belonged to code.
That is where a lot of AI-assisted builds start to go sideways. Not because the AI is useless. Not because the team is careless. Not because the model needs one more perfect prompt wrapped in YAML and blessed by a priest.
Because routing is often a job with a correct answer. And correct answers do not belong in probability land.

Non-determinism is a feature of AI systems. Treating it like a bug you can prompt-engineer away is where projects get expensive. Even platform documentation for hosted LLMs treats reproducible output as something you intentionally design for, not something you simply assume.
The Expensive Mistake
Across several large-scale enterprise data engineering engagements, I have watched the same pattern play out.
A team discovers that AI coding assistants can handle a lot of the boilerplate. They are right. Then they start pushing real business logic through the AI layer too. That is where the wheels start to wobble.
This is one of the classic problems with production ML systems: quick wins can quietly create long-term maintenance debt when model behavior starts bleeding into places where clean system boundaries used to exist. The paper Hidden Technical Debt in Machine Learning Systems calls out issues like boundary erosion, entanglement, hidden feedback loops, and undeclared consumers as ML-specific risk factors in real systems. (NeurIPS Papers)
The issue is not just that AI can be wrong. Everyone knows that by now. The more dangerous issue is that AI can be inconsistently right-looking.
Same input. Different output. No stack trace. No obvious failure. No angry red banner from the heavens. Just quiet variance sitting inside your pipeline like a raccoon in the ductwork.
If your pipeline needs to classify a transaction against a defined set of codes, that mapping either resolves to a rule or it does not. If supplier ACME-4421 always maps to Network Equipment, that belongs in code. If a cost center is missing, malformed, or conflicts with another field, maybe the AI gets involved.
But asking the AI to decide the normal path live introduces variance into a place that requires precision. That is the problem.
Think of your agent as a very fast junior engineer. It does what it understood you to want, not necessarily what you meant. It will answer confidently whether the answer is deterministic or not. It cannot tell the difference.
That job belongs to you, the architect.
The Certainty Gate
The framework I use on every AI-assisted build is called The Certainty Gate.
The idea is simple: before a task reaches the AI layer, ask whether the system already has enough information to produce the correct answer deterministically.
If it does, that work belongs in code. If it does not, AI may have a role.
A lot of failed AI projects happen because teams skip this gate. They let the AI make decisions before they have defined which decisions should be deterministic, which should be probabilistic, and which should never reach the model in the first place.
The question is not, “Can AI do this?”
The question is, “Should this have ever reached AI in the first place?”
That gate should exist before the first prompt, not after the third production incident.
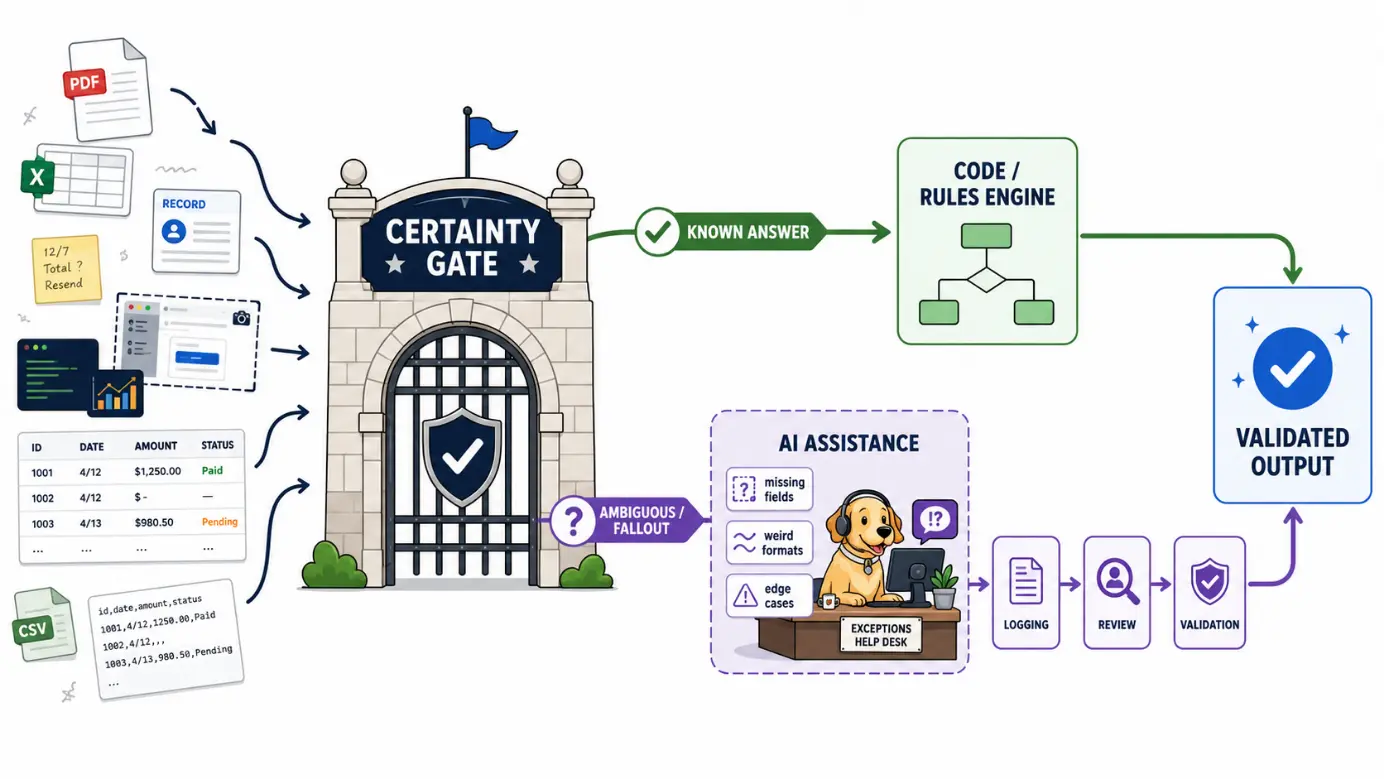
1. Put the Known Stuff in Code
Anything with a correct answer should be handled deterministically.
That sounds obvious until you watch a team ask a model to classify something their business rules already understand. If a transaction type maps to a known code, write the mapping. If a field needs to be validated against a defined schema, write the validation. If a record should follow a specific routing rule, write the rule.
Code is boring in the best possible way. It is auditable, testable, and consistent. Pass the same input and you get the same output every time. Your QA process can verify it. Your team can reason about it. Someone can inspect the logic and say, “Yes, that is the rule.”
That matters because once a business rule moves into a prompt, it becomes harder to inspect, harder to test, and harder to prove.
You can still use AI to help write the code. That is not the issue. The issue is letting AI become the place where the rule lives.
A calculator does not interpret 2 + 2 based on vibes. It returns 4. If your business logic has that kind of answer, treat it like math, not a conversation.
Before an AI touches the workflow, identify every field, flag, classification, or routing decision that has a canonical answer in your domain. Build those paths first. Test them. Make them boring.
Boring is good. Boring means the system can be trusted.
2. Let AI Handle the Fallout
AI should not be the main road. It should be the off-ramp.
Fallout means the records, inputs, or scenarios your normal rules cannot confidently process: missing fields, weird formats, conflicting values, edge cases, or new patterns nobody has encoded yet.
That is where AI earns its keep. If your rule engine returns a confident result, the AI should never see that record. There is no prize for routing clean data through a model. You just added latency, cost, variance, and a future debugging session with fluorescent lighting and bad coffee.
Let the deterministic system handle everything it can. Then send the unresolved cases to AI with a clear reason attached.
Why did this record fall out? Was a required field missing? Was the format unknown? Did two rules conflict? Was the confidence too low?
If you cannot explain why the AI got involved, it probably should not have gotten involved.
You should also track the volume. As a rough smell test, if more than 20% of your records are going to AI, your rules probably are not complete enough yet. That does not mean the AI layer is failing. It means your deterministic layer is under-built.
The ER is for emergencies. You do not route every patient through the ER because it can handle complex cases. That is how you get a hospital running like a haunted DMV.
3. Keep the Prompts Small Enough to Test
The other mistake is trying to make one prompt do too much.
You start with something simple: classify this record. Then you add a condition. Then a fallback. Then a special case. Then three output formats. Then some business logic. Then an exception for a partner system. Then a paragraph that says “be careful.”
Now the prompt is no longer a component. It is a junk drawer with an API.
This works beautifully in demos because demos are fake little terrariums where nothing truly horrible has happened yet. Production is different.
Production has malformed input, missing fields, weird encodings, legacy formats, duplicate records, and spreadsheets maintained by someone whose filing system appears to be “whatever felt spiritually correct at the time.”
When that world hits a giant multi-branch prompt, the edges get unpredictable fast.
One prompt should do one task. Not one workflow. One task.
Extract this field.
Classify this unresolved record.
Summarize this exception.
Compare these two values.
Return this output structure.
The smaller the prompt, the easier it is to test. The easier it is to test, the easier it is to trust. The easier it is to trust, the less likely you are to end up explaining to leadership why the same customer record was classified three different ways before lunch.
Prompts are not magic spells. They are components.
Version them. Test them. Review them. Roll them back when they break. Same as code.
A Simple Routing Test
Before you send work to an AI layer, ask one question:
Does this task have a correct answer?
If yes, it probably belongs in code. If no, the AI may have a role.

This is not about being anti-AI. It is about not handing your steering wheel to something that was only supposed to read the map.
Put It Together
If you take nothing else from this, take this:
Anything with a correct answer belongs in code, not a prompt.
AI is powerful at the edges of your rules. It is a liability at the center of them. Simple prompts that do one thing compound better than complex prompts that try to do it all. The earlier you put work through the Certainty Gate, the fewer fires you fight later.
I have watched teams rebuild pipelines in week six that would have taken an afternoon to design correctly in week one. The Certainty Gate is not about limiting AI. It is about deploying it where it actually wins.
This also lines up with how serious AI risk frameworks think about production systems. The NIST AI Risk Management Framework organizes AI risk work around governing, mapping, measuring, and managing risk, which is a more formal way of saying: know where AI is used, know what it controls, know how it behaves, and know who owns the risk. (NIST)
Use code where correctness is required. Use AI where judgment is required.
Confuse those two, and congratulations, you just built a slot machine with a sprint board.
One Thing to Do Today
Pick one AI-assisted workflow you are currently building or maintaining.
Find one place where the AI is making a decision, classification, mapping, routing choice, validation call, or output formatting decision. Then ask a simple question:
Could this answer be known before the model gets involved? If yes, that work should probably move behind the Certainty Gate.
Start small. Do not redesign the whole system. Pick one rule.
For example:
If a field maps to a known category, encode the mapping.
If an input must match a schema, validate it in code.
If a record only needs AI when a required value is missing, write that condition explicitly.
If a prompt is handling five branches, split out one task and test it on its own.
Then run the same input through the workflow twice.
The deterministic path should return the same result both times. The AI path should only receive the cases your rules could not confidently resolve.
That is the pattern. Code owns correctness. AI handles judgment at the edge.
The agent can help you build the system. But it should not be the system’s architect.
Further Reading
A few useful references if you want to go deeper:
NIST AI Risk Management Framework: useful framing for governing, mapping, measuring, and managing AI risk in production systems.
Hidden Technical Debt in Machine Learning Systems by Sculley et al.: a classic paper on how ML systems create maintenance debt when boundaries blur.
Azure OpenAI reproducible output documentation: a practical reminder that reproducible LLM output is something you design for, not something you assume.
Non-Determinism of “Deterministic” LLM Settings: research showing that output variance can still appear even when users expect deterministic behavior from model settings.
Stay tuned
Articles, links, and notes on data, AI, and building—roughly weekly in your inbox.